Paper Information
Title: Representation Learning from Limited Educational Data with Crowdsourced Labels
Links: https://arxiv.org/abs/2009.11222
Date: 2020.09.23
Comments: IEEE Transacitons on Knowledge and Data Engineering (TKDE\CCF-A)
Subjects: ML、AI
Index Terms: Representation learning, crowdsourcing, hard example mining, educational data.
Authors: Wentao Wang, Guowei Xu, Wenbiao Ding, Gale Yan Huang, Guoliang Li, Jiliang Tang, Zitao Liu
Notes
Abstract
- 提出了一个以分组数据为基础的深度神经网络来从有限的数据中生成更多训练样本来学习嵌入。
- 提供了一个贝叶斯置信度预估模型来捕捉众包标签中的不一致现象。
- 提出了一个困难例子选择流程来自动选取被错误分类的训练样本(通过找验证集中错误的部分来计算寻找和训练集相似的元素)。
- 将模型运行在三个真实的数据集中、并提供了综合分析。
Introduction
- 小样本学习和不一致众包标签的研究都非常多,然而研究用小样本和不一致的众包标签来进行表征学习的却非常少,更不要说只针对教育领域的研究。
- 提出的三个问题:
- 如何充分利用有限且不一致的众包标签?
- 如何建立一个众包标签的表征学习框架?
- 如何让这个学习过程更加高效?
- 主要贡献
- 提出了一个高效的特征学习框架来从有限和不一致的数据中学习。
- 一个困难例子挖掘策略让训练过程动态地在每个迭代中选取最难训练的例子。
- 利用该模型对三个教育数据集进行了实验,并和不同的策略进行对比。
Related Work
- 目前的小样本学习主要是针对非常少的而且是无噪声的样本,但本文的研究对象是较少的众包标签样本,因此不适用。
- 目前的众包标签学习模型都是用于解决数据的噪声和不一致性,但是当样本较少时则不具有泛用性。
- 在困难例子挖掘中没有分析当前的弊端,而是直接阐述了他们的策略。
Problem Statement And Notations
Notations
对于每个样本 $xi$,我们假设其标签集 $y_i$ 被 $d$ 个工人打上了二分类标签,其中 $y_i =[y{i,1},y{i,2},…,y{i,d}]$, 其中 $y_{i,l} \in \lbrace{0,1}\rbrace$,$l = [ 1,2,…,d\space]$。
以下是具体的公式符号约束:
Crowdsourced Label Confidence
其中,有一点特别需要注意,对于每一个样本 $x_i$,它也许会同时对应着多个标签,同一个正样本可能由不同个数的 1 组成,因此我们需要把这种差异考虑进去,将其定义为众包标签的置信度。
Hard Example
我们称 $x_i$ 为一个困难样本,当它和验证集中某个被错分类的样本 $v_i$ 最为相近,这种样本可能在应用不同选择策略时出现不一样的样本,论文中默认选择余弦函数来计算 $x_i$ 和 $v_i$ 之间的距离。
The Proposed Framework
Grouping Strategy
从 $X^+$ 中选择两个正样本,从$X^-$中选取 $S-2$ 个负样本,将这 $S$ 个样本作为一组。
那么有 $gj=\langle{x^+{a^j1}, x^+{a^j2}, x^-{a^j3},…,x^-{a^j_S}}\rangle$。对于整个训练组,有 $g=\lbrace{g_1,g_2,…,g_k}\rbrace$。
对于每一组$g_j$,我们都将其作为深层神经网络(DNN) 的输入,从而获取到低维度的输出向量。在 DNN 中我们通过多层全连接非线性投影来学习特征。
Model Learning
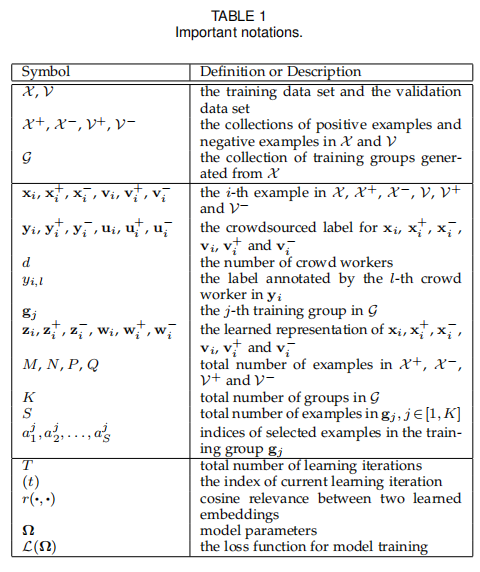
我们定义一个后验概率为给定 $x^+{a^j_1}$,计算 $x^+{a^j_2}$ 出现的概率,这个概率通过余弦函数和Softmax函数组成,其定义如下图所示:
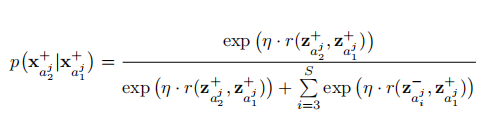
$z$ 代表的是学习后的集合,$r$ 代表的是余弦函数,$exp$ 为指数函数,$η$ 则为Softmax函数的超参数,为了使我们模型预测的向量更准确,应该让正样本在嵌入空间中尽量靠近,并且让正负样本尽量远离。因此,我们最大化这一个后验概率便可达到此目的。为了让模型使这个概率尽量变大,因此我们要定义一个损失函数,当概率越大时,损失函数越小,模型的目的便是最小化这个损失函数。损失函数定义如下:

Bayesian Confidence Estimation
让 $δi$ 为某个样本众包标签的置信度,一个常规的方法是将其看作一个符合伯努利分布的样本来计算其置信度。即: ${\hatδ^{Bernoulli}_i}=\sum{j=1}^{d} {y_{i,j}/d}$ 。
但由于在当前的问题中,我们的众包标签数目十分有限,因此用上述方法来进行极大似然估计会有欠佳的表现,因此采用 Beta 分布来构造置信度。即:${\hatδi}= \frac{α+\sum{j=1}^{d}y_{i,j}}{α+β+d}$。
在加入了置信度估计后,目标函数更新为:
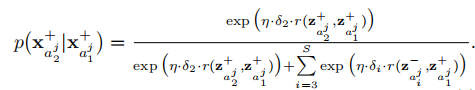
Adaptive Hard Example Selection
该过程可分以下几步进行描述:
- 在每个训练迭代中,根据该次迭代的参数来对验证集进行评估,并将错分类的验证集加入到集合 $V_{miss}(t)$ 中。
- 对于 $V{miss}(t)$ 中的每个样本,我们选取一个和其距离最近的训练样本,这个距离使用余弦函数来进行评判,最终得到 $X{hard}(t)$ 。
- 类似地,我们将 $X{hard}(t)$ 进行分组,得到分组后的集合$g{hard}(t)$ 。
- 在 $(t+1)$ 次迭代,我们将训练组 $g(t+1)$ 定义为 $g(t+1)=\lbrace{g{base},g{hard}(t)}\rbrace$,其中 $g_{base}$ 就代表着原始的分组训练集。
该迭代过程将一直重复到预测结果收敛或达到最大迭代次数才结束。
经过这几步的介绍后,我们可以得到模型的架构图:
The Representation Learning Algorithm
模型的训练过程可被总结如下:

此外,还有两个训练小技巧需要特别提醒一下:
- 在前五轮的训练中,暂不启用Hard Example Selection,确保模型有一个较为稳定的开始。
- 此外,为了在每次训练中有一个稳定的表现,当测试集的正确率小于0.7,便在这次迭代中不使用Hard Example Selection策略,而使用基础的分组训练集来代替。
Experiments
Experimental Settings
用于训练模型的三个数据集的信息如下:
- fluency-1&2:5位标注者对743个1、2年级孩子回答数学问题的音频流利程度进行评判,即进行二分类,0代表不流利,1代表流利。
- fluency-4&5:类似于上面的数据,收集了1965个4、5年级的音频数据,请了11个标注者进行标注。
- preschool:从学前儿童的演讲比赛中收集了1767个演讲片段,每一段被11个标注者评分。
随后,将三个数据集随机打乱为三个集合,即训练集、校验集和测试集。测试集的数据邀请专家来标注,作为评价的基准。由于原始的数据集均由音频组成,因此需要进行特征提取才能够交付模型来训练。
Raw Feature Extraction
对于原始数据集,我们分两类特征进行抽取,第一类为韵律特征,第二类为语言特征。韵律特征有音量、信号能量、梅尔频率等,可以通过一些工具 (OpenSMILE) 进行抽取。通过演讲自动识别模型来获取语义特征,如:中间词的数量、重复的次数等。
最终,抽取后的特征可被分成以下几类:
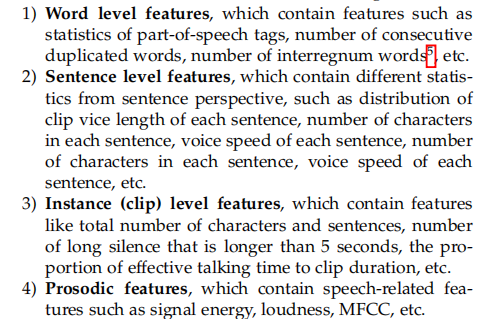
其中,前两个数据集的特征均为语义特征,而最后一个数据集的特征为韵律特征。
Baselines
下面将数据集试验于三种不同的 Baseline。
- 流行的分类模型(数据集的众包标签使用众数决定)
- LR
- GBDT
- SVM
- 有限样本的特征学习模型(数据集的众包标签使用众数决定)
- SiameseNet
- FaceNet
- RelationNet
- 基于有限众包标签样本的特征学习模型
- RLL-Bayesian
- RECLE(本论文提出的模型)
Experimental Results
对于第二第三组 Baseline,我们用线性回归对其学习到的特征进行二分类。对于第一组,我们直接采用原始的数据来训练评估。下面是这三组模型在第三组数据集的表现:
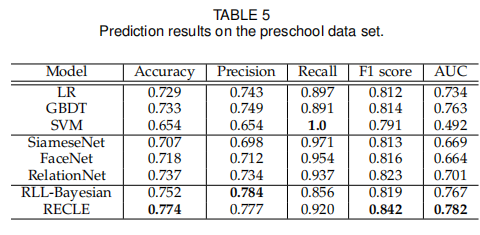
我们可以得到以下几点结论:
- 第二第三组模型拥有Grouping-based Strategy,因此可以获得更充足的数据,有着更好的表现。
- 因为第一第二组的模型都需要对标签进行推测,而没有引入置信度估计,因此会导致一些信息损失。
- 所有的模型在前两个数据集中都表现得更好,推测其原因是因为最后一个数据集的韵律特征没有语义特征有代表性。
Evaluation of Learned Representations
为了能够更直观地观察模型学习到的特征是否有效,我们对原始数据和学习后的数据作图显示,可以发现在学习后的嵌入空间中,标签相同的数据距离也靠得更近,更有利于分类模型的学习。
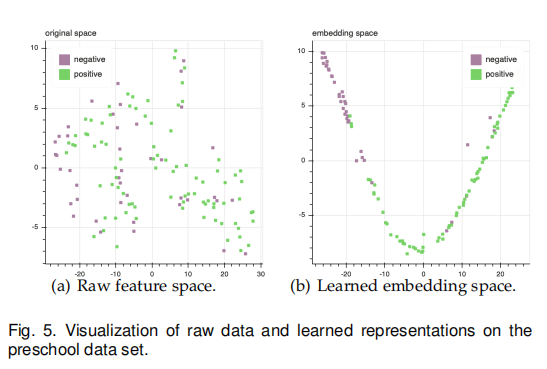
Impact of Different Distance Metrics
这部分采取了三种不同的距离来用于模型的置信度估计(其他的参数设定保持一致),经实验发现,余弦距离在一、二数据集上表现更优,即语义特征,而欧式距离则在韵律特征上表现更好。
Impact of Imbalanced Data Distribution
这部分阐述了将原始的 Grouping Strategy 换为了选取 S-2 个负样本和 2 个正样本,其他的参数保持不变,之后在第二个数据集上进行实验,发现结果和原来的策略类似。
Conclusion And Future Work
这篇论文主要解决了有限的众包标签数据问题。为了解决小样本数据带来的不一致性与稀缺性,提出了以下框架来解决三个问题:
- 自动组成样本组,扩充神经网络的训练数据。
- 引入了众包标签置信度评估模型来对不一致性进行衡量。
- 自动选择训练集中较难训练的样本来让训练过程更充分高效。
为了评估我们的模型,我们将模型与众多其他的 Baseline 作对比,实验证明我们的模型确实能够解决众包标签有限和不一致的问题,同时学习到高效的嵌入信息。
在未来,作者计划从三方面继续开展我们的工作:
- 计划将众包工人得个人信息融入到模型中。
- 计划将学习更多的高级技巧来将训练组从不同的训练阶段中进行结合,从而改善模型预测准确率。
- 计划将对其他有限的众包标签数据进行更多的实验,比如癌症诊断问题和生物医药图像问题等。
Reproduction
论文作者已提供了该研究的代码,但在克隆到本地后进行实验时仍有一些问题。在阅读其代码结构后,本人对其进行debug,并已将论文的核心模型——RECLE在本地跑通,并在代码中加入了注释以便理解,详情请见仓库。