SCNU-CS-2018-DataMining
这一次整理的是数据挖掘课程项目,分为平时项目与期末项目。以小组为单位,课程要求使用数据挖掘方法进行数据分析和建模,最终需要提交代码、论文,期末项目还需要进行小组汇报,具体的内容请参见 Github。
项目结构
Project-1为平时项目,Project-2为期末项目,项目结构与具体的使用方法请参照下面的内容。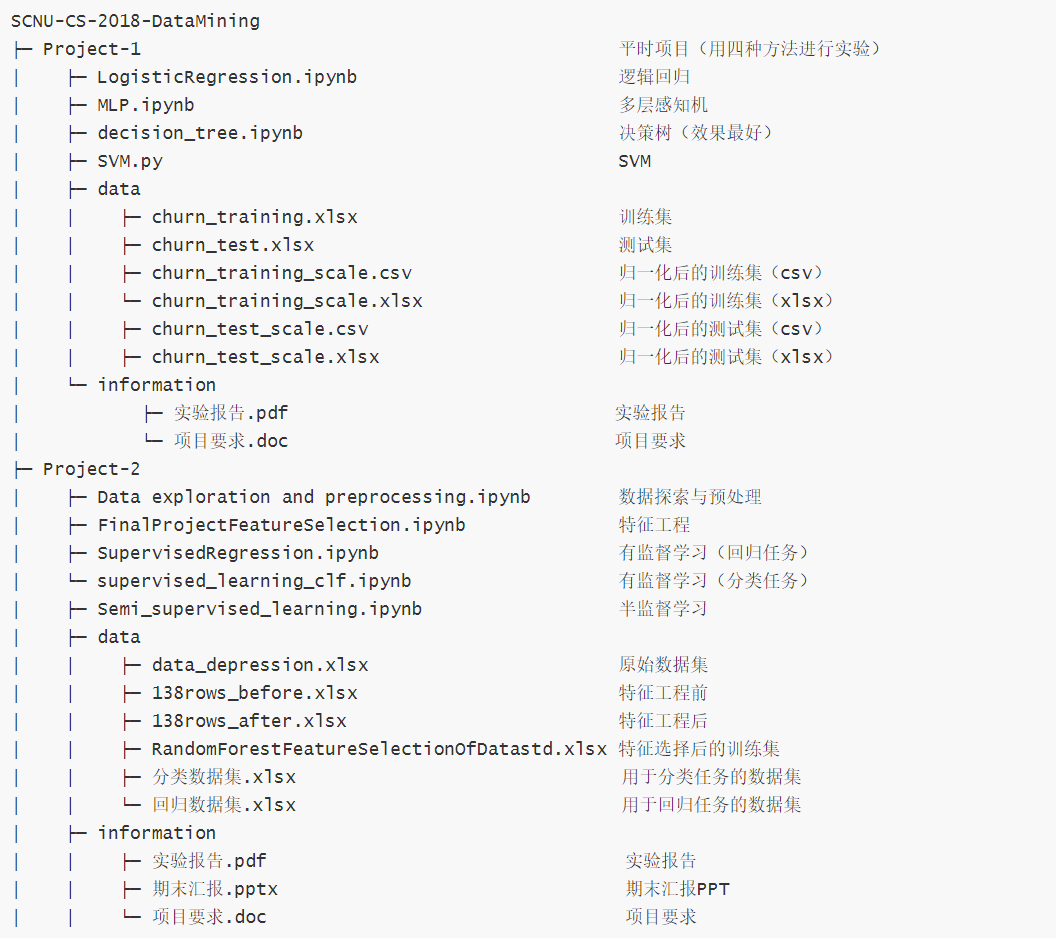
项目一简介
客户流失管理:根据多个客户的数据,利用数据挖掘方法进行建模,使模型能够通过用户的信息来预测用户是否已经流失(二分类问题:1为流失、0为无流失)。在这个项目中,你需要使用决策树(预剪枝和后剪枝)、多层感知机、逻辑回归、决策树来进行实验,提交每个模型的混淆矩阵,并在最终的报告中呈现各个模型的性能。
项目二简介
抑郁症 HAMD 评分预测:数据集“data_depression.xlsx”包含两个数据表单:“抑郁脑电图” 和 “针刺效益、前后脑电图”。表单 “抑郁症脑电图” 字段有姓名、性别、年龄、HAMD评分、以及针刺前脑电节律波幅指数和节律指数。表单“针刺效益、前后脑电图”字段主要有姓名、针刺前脑电指标和针刺后脑电指标。其中,表单 ”针刺效益、前后脑电图“ 中患者只是表单抑郁症脑电图中患者的一部分。根据17-item HAMD抑郁症评价量表,字段HAMD评分是患者抑郁症程度评价。
提示:在预处理中需要将同一个患者的数据拼接成一行,表单一中的数据为针刺前的脑电指数,有 HAMD 评分,可以进行有监督学习;表单二中加入了部分患者无 HAMD 评分的针刺后脑电数据,可以将脑电前后数据进行拼接,从而进行半监督学习。
开发环境和使用方法
为了能够实时查看到数据,我和项目成员选取了 Jupyter Notebook 的方式在 Colab 上进行实验。如果你此前没有配置过相关的环境,在此极力推荐在线的 Jupyter Notebook环境(Colab , Kaggle)进行实验,以免花费太多不必要的精力在配置环境和安装依赖库中。
所有 .ipynb 文件 均可在 Colab 上直接运行,但不排除会因为没有 pip 安装库等原因导致一些小 bug 出现。
写在后面
由于项目以小组单位进行开发,所以各位成员的代码风格有一定的差异,也不排除某些方面的问题有所忽略,如发现有错误或不足,十分欢迎 issue 或 pr。希望能帮助到学习该门课程的同学。