Paper Information
Title: Modeling Global and Local Node Contexts for Text Generation from Knowledge Graphs
Links: https://arxiv.org/abs/2001.11003
Date: 2020.06.22
Comments: Transactions of the Association for Computational Linguistics (TACL)
Subjects: KG、AI
Index Terms: Knowledge Graphs, Text Generation
Authors: Leonardo F. R. Ribeiro, Yue Zhang, Claire Gardent, Iryna Gurevych
Notes
Abstract
- 融合了 Global Node Encode 和 Local Node Encode 来构造新的神经网络,从而更好地学习上下文节点嵌入。
- 运用 AGENDA 数据集和 WEBNLG 数据集进行实验,各项评价指标得到了提升。
Introduction
- 图到文本的生成指的是根据输入的图结构生成对应的自然语言文本,图可以指的是语义表示或知识图谱,文本包括单一的句子或包含多行句子的完整文本,而本文的任务是根据知识图谱生成完整文本。
Encode:
- Global Node Encode:优点为考虑了大量的上下文节点,但因为将所有节点都看作和其他节点简单相连而忽略了图的拓扑结构。
- Local Node Encode:将每个节点的相邻节点情况,即图的拓扑结构考虑到其中,但其缺点是难以构造图中相距较远节点的关系。
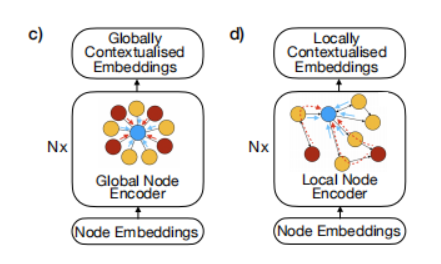
主要贡献
- 首次融合了 Global Node Encode 和 Local Node Encode 来构建 graph-to-text 模型。
- 首次提出了一个将 Global Node Encode 和 Local Node Encode 进行组合的 GAT 架构。
Related Work
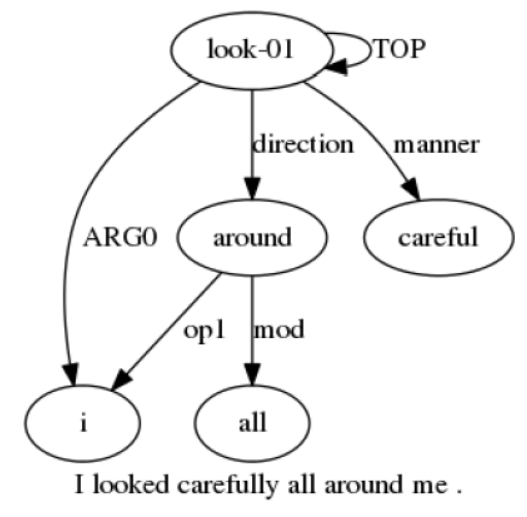
- AMR-to-Text:AMR 代表 Abstract Meaning Representation Graphs,是图的其中一种,具体的例子可参照下图,将 AMR 转成文本的已经有多个研究,使用的方法包括但不限于:GNN、GCN、LSTM 等。
KG-to-Text:知识图谱和 AMR 相比更加稀疏,有着更庞大数量的关系且没有固定的拓扑结构;不同数据集的知识图谱会有着较大的差异,这使得生成文本的过程更加困难。该任务常用的方法包括但不限于:LSTM/GRU、GNN、GCN、Transformer。
加入图的全局信息:为了更好地完成 graph-to-text 的工作,越来越多的研究加入了全局的节点信息,大部分的工作都是通过扩展图的结构,在图中加入一个全局节点来完成的。
Graph-to-Text Model
论文的这一部分包含以下内容:
- 如何将输入的数据转换成关系图。
- 描述如何使用 GAT 构建 graph encoders。
- 描述将 global encoder 和 local encoder 结合的方法。
- 描述 decode 和训练模型的过程。
Graph Preparation
每个 KG 都是一个由带权边组成的有向图,它的表达形式为:$G_e = (V_e, ε_e, R)$,其实体节点的表示为 $e∈V_e$,其带权边集为 $(e_h, r, e_t)∈ε_e$,代表了实体 $e_h$ 和 $e_t$ 存在关系 $r∈R$。
有一点和其他方法不同的是,这里将图中的实体集看成是一组节点的集合,其中每个组成实体的符号 (token) 都是一个节点。例如,KG 中有一个实体是 “node embedding”,那么该实体则由两个节点组成,分别为 node 和 embedding。各节点之间的边的关系对应着其所属实体之间的边的关系,即边 $(u,r,v)∈ε$ 当且仅当存在一条边 $(eh, r, e_t)∈ε_e$,且 $u∈e_h$, $v∈e_t$ 。节点 $v$ 可以表示为一个嵌入 (embedding):$h_v^0∈R^{d{v}}$。
这一种图的表示方法有着很好的表达能力,但它也有一个副作用,便是消去了原实体中的单词顺序信息,为了避免该种影响,应该在 embedding 中同时加入对应 token 的位置信息。
Graph Neural Networks (GNN)
GNN 的工作原理为:通过学习节点的上下文节点表示和其边信息,通过信息传播机制来迭代更新当前节点的 embedding。第 $l$ 层 GNN 关于 $v$ 的上下文节点表示的公式为: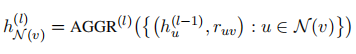
其中 $AGGR^{l}(.)$ 是 $l$ 层上的聚合函数 (aggregation function),$r{uv}$ 代表了 $u$ 和 $v$ 之间的关系,$N(v)$ 是 $v$ 的所有上下文节点集合,即那些与 $v$ 相邻的节点。我们可以将得到$h{N_{(v)}}^{(l)}$ 用于更新第 $l$ 层节点 $v$ 的表示,公式为:
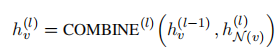
在 $L$ 次迭代后,一个节点的表示包含了当前迭代中的上下文节点信息。$AGGR^{l}(.)$ 和 $COMBINE^{l}(.)$ 函数的选择根据 GNN 的不同而不同,常见的 $AGGR^{l}(.)$ 是对 $N(v)$ 求和,而$COMBINE^{l}(.)$ 函数则通常对表示向量进行拼接 (concatenation) 。
Global Graph Encoder
全局图编码器在更新每个节点的表示时需要考虑全图的节点,这里采用了注意力机制作为消息传递机制,并将其扩展成为 GAT 结构。该编码器的公式如下所示:
其中 $Wg$ 是模型的参数,注意力权重 $a{vu}$ 的公式为:
其中 $e_{vu}$ 用于权衡节点 $u$ 对 $v$ 的重要性,其公式为:
为了捕捉到节点之间的不同关系,一共设计了 $K$ 个独立的全局卷积,将其计算完毕后进行拼接,有
最后,$COMBINE^{l}(.)$ 函数由 LayerNorm 和 FFN 结构组成,其公式推导为:
Local Graph Encoder
全局编码层中没有考虑到节点之间的边的信息和图的结构,为了补充这些信息,需要结合局部编码器到模型当中。其 $AGGR^{l}(.)$ 函数为:
其中 $Wr$ 代表了节点 $u$ 和 $v$ 之间的关系,注意力函数 $a{vu}$ 的计算公式为:
$e_{vu}$ 的计算公式为:
其中 σ 是激活函数,$a$ 和 $Wv$ 是模型参数。同样地,这里将 $K$ 个拼接起来,得到 $\hat{h}{{N(v)}}$。那么$COMBINE^{l}(.)$ 函数的定义为:
Combining Global and Local Encodings
直观地来说,合并两种编码器一般有两种方法,第一种方法是并行结构,也就是将全局和局部节点得到的表示进行拼接。第二种方法是级联的结构,首先得到一个全局编码器的表示,随后将其作为局部编码器的输入。
这两种方法的每一层都只包含单一的一种编码器,现在提出设想:将两种编码器在层内进行合并,再重复一定的次数从而得到最终表示。层内合并的方法也是类似的,有并行合并和级联合并两种方法,因此总共有四种模型结构,它们如下图所示:
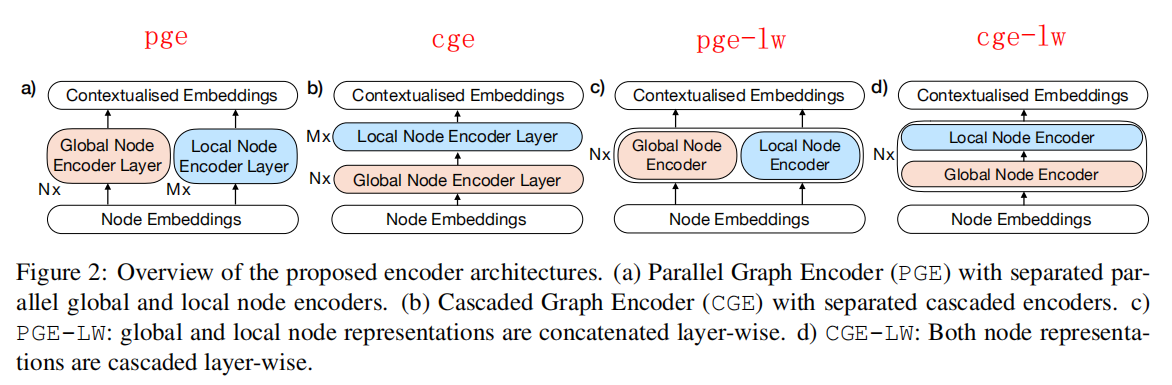
Decoder and Training
Decoder 用于根据 Encoder 所学习到的图表示来生成对应的文本,这里的 Decoder 使用的是著名论文 “Attention is all you need” 中的 Decoder 结构。在训练中的其中一个挑战是需要生成包含多行文本的输出,因此在训练过程加入了 length penalty。
Data and Preprocessing
AGENDA
该数据集包含了12个顶级 AI 会议的论文摘要,每个样本都包含了论文的标题、论文摘要和其对应的知识图谱。在预处理中同时将标题中的每个 token 当作一个 node,和知识图谱中的所有 node 合并构成图。
WebNLG
该数据集包含了从 DBPedia 抽取出来的知识图谱,该数据集中包含了较多的边数目,为了防止维度爆炸,作者使用了正则化来定义模型的关系权重。此外,作者还用到了 Levi Transformation,将关系边转化为一个结点,将关系对应的两个节点与其相连。
下图是这两个数据集的概览:

Experiments
项目使用 PyTorch Geometric 和 OpenNMT-py 进行实验,Adam 优化器的参数选取分别为 $β_1 = 0.1$ 和 $β_2 =0.2$ ,学习率随着训练的轮次而逐渐上升。作者采用了 byte pair encoding 的方法,从而使实体词汇变成更小的 sub-words。
在评估方面,使用的 metrics 有:BLEU、METEOR、CHRF++ 等。在层次结构模型中,层次的选择从 {2,4,6} 中选择,在普通的并行和级联模型中,全局编码层和局部编码层的层数分别从 {2,4,6} 和 {1,2,3} 中选择,隐藏编码器的维度从 {256,384,448} 中选择。
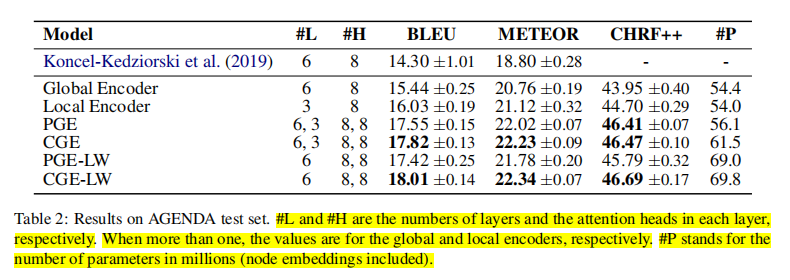
Results on AGENDA
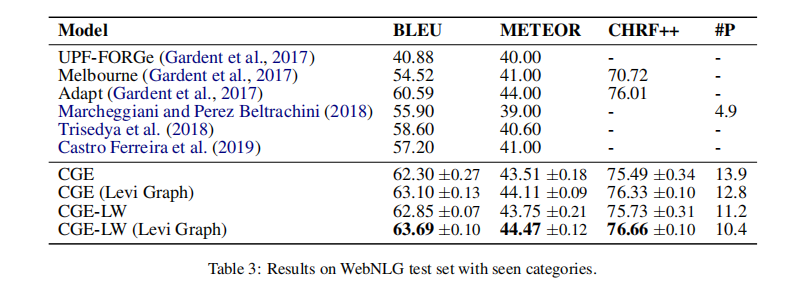
Results on WebNLG
从 AGENDA 数据集的实验可以看出 CGE 的模型效果更好,因此在 WebNLG 实验中没有再用到 PGE。
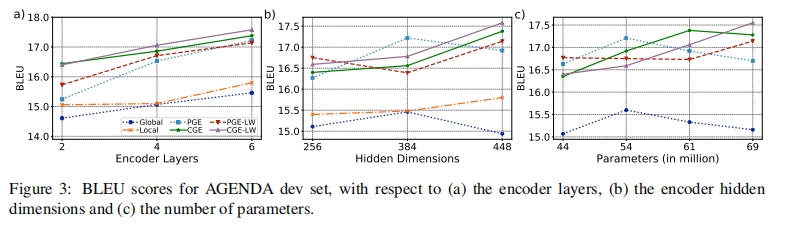
Development Experiments
经过实验,作者发现了以下几个结论:
- 编码器的层数越多,效果越好
- 编码器的向量维度并不是越高越好,因不同模型而异
- 对于一些模型来说,进一步增加编码器的层数和参数数量能进一步提升模型性能
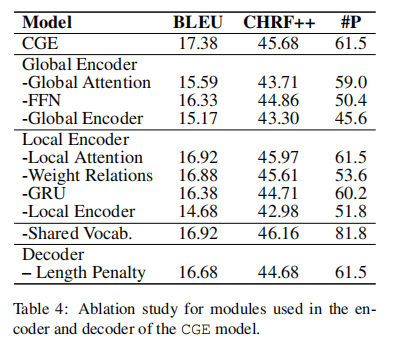
Ablation Study
在这一部分中,作者将模型中的某些部分消去,从而查看去除这些部分的模型结果是怎样的。具体的结果如下图所示:
Impact of the Graph Structure and Ouput Length
- 在 AGENDA 数据集中,图的规模越大,模型的效果越好;而 WebNLG 的结果则恰恰相反,规模越大,效果反而越差。
- 当生成的句子越长的时候,模型的效果会下降,尽管加入了 length penalty,生成得到的文本长度与原文本仍有一定的差距,这也是作者后续所要优化的方面。
Human Evaluation
为了进一步评估生成文本的质量,作者聘请了人类对 baseline、本文提出的模型所生成的文本和原来的文本进行评估,评估的两个方面为文本的适当性和流畅性,结果如下图所示,并得出了以下的结论:
- 本文提出的模型的人工评测效果在各类的样本中都比 baseline 要好。
- 当图的规模增大时,模型的评测效果变差。
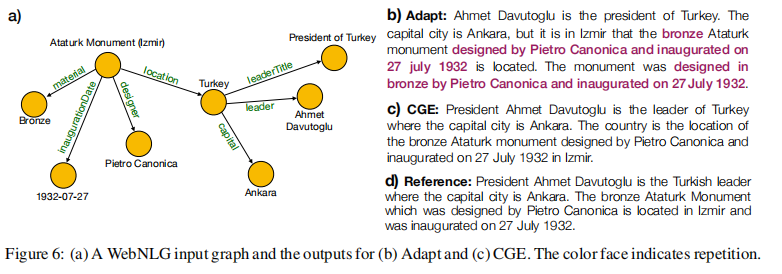
下图是其中一个 KG 和其对应的三种文本:
Additiional Experiments
在这一部分,作者对模型的一些其他部分进行进一步的探究,探究所得出的结论如下所示:
- Sharing vocabulary 策略对小数据集更为重要,而 length penalty 则对大数据集更为重要。
- 全局编码器中注意力权重最大的点往往是较远的结点,而局部编码器则是较近的结点,这和认知是相符的。
Conclusion
在本论文中,作者提出了一个结合注意力机制的 KG-to-Text 神经网络结构,同时在模型中结合了全局编码器和局部编码器来改善文本的生成。经过实验分析,在级联结构下构建层次模型结合两类编码器,可以达到 state-of-the-art。同时,作者提出了以下几点未来的研究方向:
- 进一步研究全局和局部编码器的组合方式来提升效果。
- 尝试在图中结合预训练的上下文词嵌入。
- 继续探究长文本生成和原文本差距较大的原因。
Reproduction
论文作者已提供了该研究的代码,但仓库中依然缺少数据集。
本人基于作者的指引,下载了AGENDA数据集进行试验与debug,使其能够在Kaggle平台上成功运行。